
Challenges in API integration
- Nazima
- 6:31 pm
- May 11, 2026
One API Glitch, Zero Users: The Night We Lost 5,000 Signups
It happened during a midnight deployment.
Traffic was climbing fast. Signups were rolling in every second. Then suddenly—everything stopped.
No crash screen. No dramatic server explosion. Just silence.
Our third-party API integration had failed quietly in the background, and within minutes, nearly 5,000 new users were stuck in limbo.
That night taught me something every developer, startup founder, and engineering team eventually learns:
A product can have great code, a polished UI, and solid infrastructure—but weak API integration can still break the entire experience.
After working with multiple teams and debugging integrations across different products, I’ve noticed the same problems appear again and again. Here are the biggest API integration challenges that cause real damage—and the fixes that actually work.
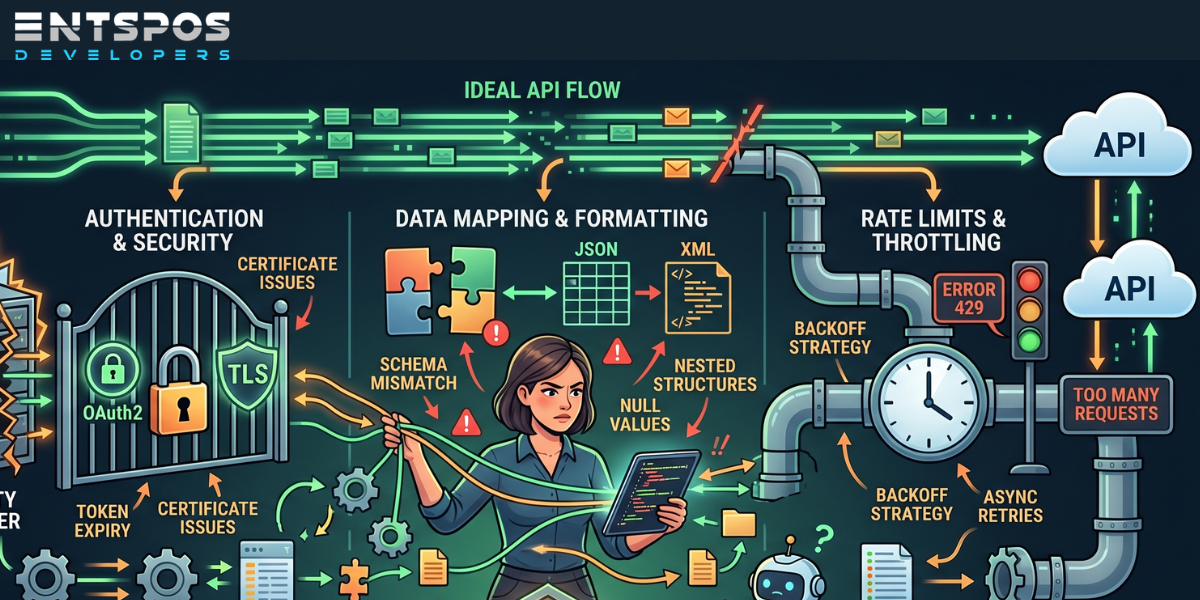
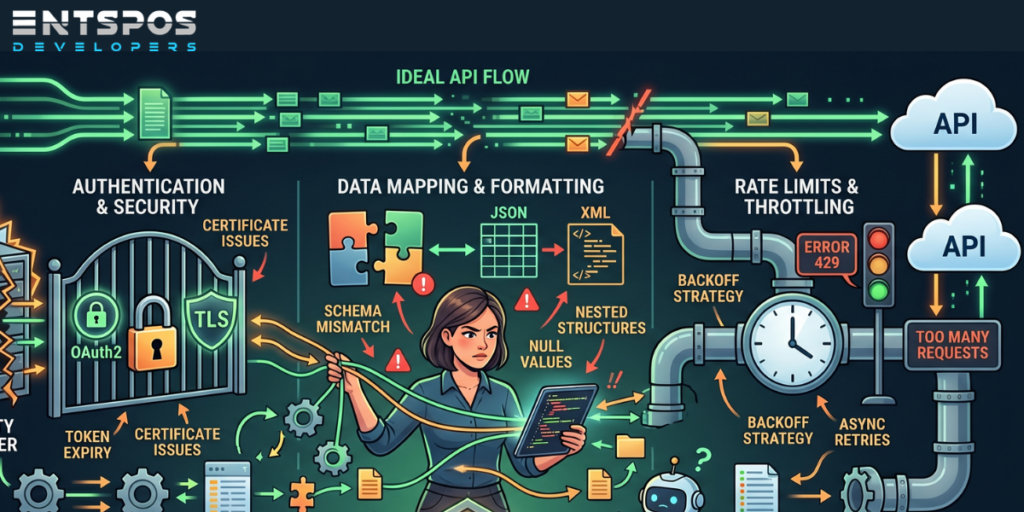
1. Authentication Problems That Break Everything
Authentication failures are one of the most common integration issues, especially when multiple services are involved.
A token expires unexpectedly. Permissions change. OAuth scopes mismatch. Suddenly every request starts returning 401 Unauthorized.
Why this becomes a serious problem
OAuth implementations differ between providers
API keys and secrets get exposed or mismanaged
Multi-tenant systems create permission confusion
Refresh-token logic is often poorly handled
What helped us
We centralized authentication instead of handling it separately across services. Tools like Okta, Firebase Auth, or Auth0 simplify token management and role control.
Adding middleware-level validation also helped us detect authentication failures before requests reached critical services.
The result: authentication-related API errors dropped dramatically.
2. API Version Changes That Quietly Break Your App
One of the most frustrating things about third-party APIs is that providers update them constantly.
Sometimes an endpoint changes format. Sometimes a field disappears. Sometimes pagination behavior changes without warning.
Your code keeps running—but your data becomes unreliable.
Common versioning problems
Breaking changes during active releases
Legacy clients depending on old response structures
Frontend parsing failures from modified payloads
Different teams using different API versions
Better approach
Use explicit API versioning strategies such as:
http
API-Version: 2.0
Contract-testing tools like Stoplight or Swagger/OpenAPI validation help ensure both teams follow the same schema expectations.
Versioning discipline prevents “silent failures” that are hard to detect in production.
3. Rate Limits That Destroy Performance During Growth
Most APIs look generous during development.
Then launch day arrives.
Suddenly your application exceeds quota limits, retries explode, and users start experiencing delays or failed actions.
Why rate limits spiral out of control
No monitoring of API quotas
Aggressive retry loops multiplying requests
Shared API keys across environments
Confusion between per-user and global limits
What works in production
Redis caching for repeated requests
Exponential backoff with jitter
Queue systems for burst handling
Monitoring tools like Prometheus or Grafana
Caching alone can reduce external API costs and massively improve reliability under load.
4. Data Structure Mismatches That Waste Hours
This is where integrations become exhausting.
One API sends dates as timestamps. Another sends strings. Nested JSON structures differ slightly between environments. Nullable fields suddenly appear.
Small inconsistencies create large debugging sessions.
Typical causes
Unannounced schema changes
Mixed protocols like REST and gRPC
Weak validation layers
Inconsistent serialization formats
Smarter solution
Validate and normalize incoming data aggressively.
Tools like:
JSON Schema validators
Zod
tRPC
TypeScript type enforcement
…help catch issues before they spread into your application.
Strong typing turns unpredictable integrations into maintainable systems.
5. Latency and Timeouts That Slowly Kill User Experience
Not every failure is immediate.
Sometimes APIs technically work—but they respond too slowly.
A few extra seconds across multiple services can completely ruin application performance.
What usually causes it
Too many network hops
Slow upstream providers
Missing timeout configurations
Serverless cold starts
No circuit-breaker protection
Better architecture choices
Use gRPC where low latency matters
Add request timeouts everywhere
Implement circuit breakers
Use reverse proxies like Envoy
Example:
javascript
fetch(url, {
timeout: 5000
})
Without proper timeout handling, slow services can consume resources indefinitely.
6. Reliability Problems From Third-Party Providers
This is the harsh reality of modern software:
Your application may be stable, but your dependencies might not be.
Even providers promising “99.9% uptime” still experience outages, degraded performance, or regional failures.
Hidden reliability risks
No fallback providers
Vendor lock-in
Compliance conflicts across regions
Regional API outages
How teams reduce risk
Add failover mechanisms
Use API gateways like Zuplo
Mirror critical services across cloud providers
Design systems to degrade gracefully
The goal is not perfect uptime.
The goal is ensuring one provider failure does not take down your entire product.
7. Weak Testing That Lets Bugs Reach Production
Many API integrations pass staging tests and still fail in real-world traffic.
Why?
Because mocks rarely behave exactly like production systems.
Common testing gaps
Outdated mock responses
Missing edge-case payloads
Unrealistic load simulations
No contract testing between services
Better testing stack
WireMock for realistic API stubs
Artillery or k6 for load testing
Consumer-driven contract testing
Chaos engineering practices
One properly simulated failure scenario can prevent weeks of production damage.
Final Thought: API Integration Is Infrastructure, Not Glue Code
A lot of teams treat integrations like a secondary task.
But APIs are no longer just connectors between services—they are part of your product’s core infrastructure.
The strongest applications are not the ones with the most features.
They are the ones that remain reliable when authentication fails, providers change behavior, traffic spikes, or dependencies go down.
If you improve even one area today—authentication, testing, versioning, monitoring, or resilience—you reduce the chance of your next deployment turning into a disaster.
Because in modern software, users rarely see the API.
But they always feel it when it breaks.













